Distractions
Ihave no idea why I am doing this. It’s sort of depressing, is really difficult, and will almost assuredly lead to nothing. It’s something to concentrate on, I guess. It’s medatative, in a way. Whatever.
science writer voice engaged
I fucked up
Two weeks ago I posted about some social simulation stuff I was doing and that the stupid simulation wasn’t doing what I expected. Markers turned on produced bigger populations and weird oscillations, no widening trust gap, no obvious stratification. I worried I’d accidentally built a defense of tribalism. I promised four diagnostics and to come back when I knew more.
I ran them. I also ran a lot of other things. I know more than I knew. The short version: the original “tribalism helps coordination” reading was wrong. The actual story is weirder, and once I saw it I felt a lot better about the project, not because it gave me the answer I wanted, but because the machinery it’s pointing at matches the world more honestly than what I thought I was looking for.
What the diagnostics actually showed
I checked whether agents were segregating to same-marker partners. They weren’t, within-group and across-group trust track each other tick-for-tick, so cross-group experiences are happening and being learned from. Same-group and cross-group ventures happen at roughly the rates you’d predict from a population that’s randomly mixing, with a small homophily nudge from the trust generalization. What’s not happening in Reading 2 is that the trust gap was zero because there were no cross-group interactions to build cross-group trust on.
What is happening is that within-group and across-group trust track each other. They both go up at the same rate, they both go down at the same rate. Generalization with no actual quality difference between groups doesn’t fork the population into in-group and out-group expectations. It homogenizes the priors toward the population mean. Everyone learns “the typical agent is about this trustworthy,” and the group label drops out as informative.
So reading 1 was wrong too. Markers don’t function as a coordination signal in the way I thought. They function as a noise channel that gets averaged away.
That cleared a lot. It also left me with a question: if pure trait-generalization isn’t enough to produce stigma, what is?
Adding loss-aversion
Real humans don’t update trust symmetrically. Losses sting more than gains
soothe. There’s a long literature on this, going back to Kahneman and
Tversky in the seventies. So I added a knob: success raises trust by gain,
failure lowers it by loss, and I let loss > gain.
That changed everything.
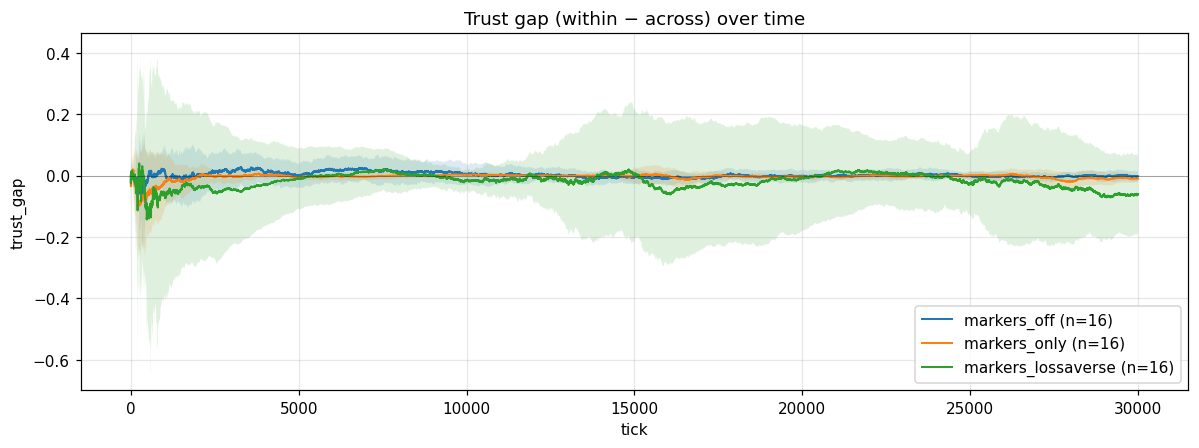
With loss-aversion on, the trust gap widens. The mean magnitude across seeds jumps about nine times what the symmetric control produces. There is a real, robust stigma signal in the simulation. So I had a finding.
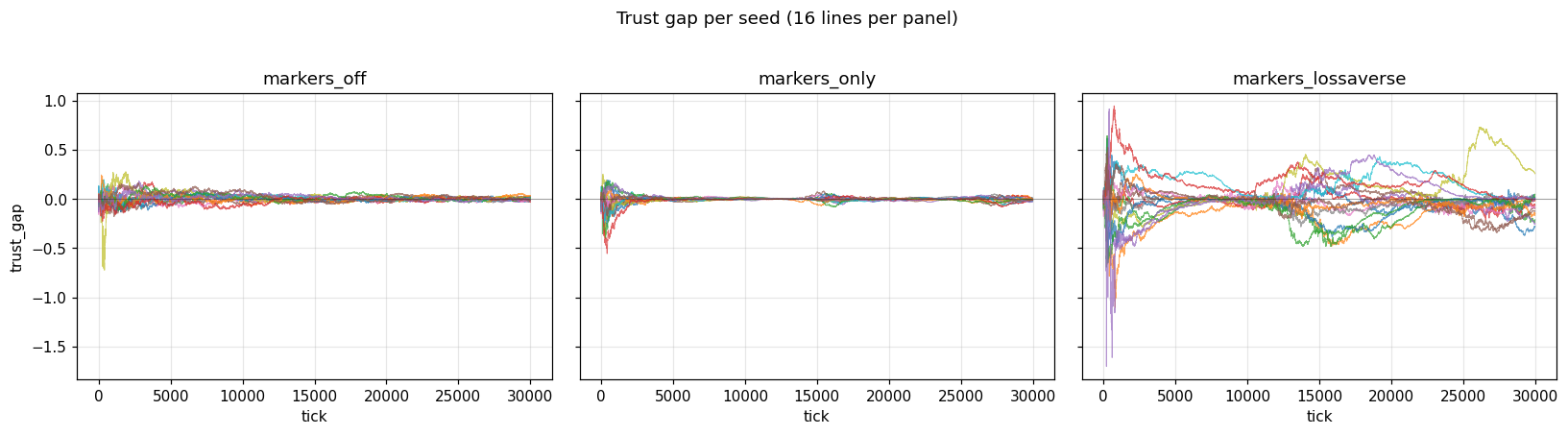
Then I looked at the per-seed traces and got the actual interesting result.
The mean trust gap, averaged across seeds, stays near zero. But each individual seed locks onto a large nonzero gap, and the sign is random. Some seeds end up with the population distrusting group A. Some end up with the population distrusting group B. Some have it both ways at different points in the run before settling. Average them all together and they cancel. Look at any single one and there’s a big stable gap.
Stigma is real in this simulation. The target of the stigma is arbitrary.
What this means
I think this is the thing I was actually looking for, and I didn’t know it until I saw it.
The story I went into the project with was something like: a marginalized group exists, the dynamics of cooperation pin marginalization onto it because the group is distinguishable and history put it in a worse position. The marker tracks the wound. That’s a coherent story and I’m sure something like it operates in the real world for some cases.
But there’s another story, and it’s the one this simulation seems to be telling. The story is: in a system with asymmetric trust updates and any arbitrary group labels at all, some group is going to end up as the distrusted one. Which group is mostly historical accident. Once it’s locked in, it stays locked, because loss-aversion means recovery from a bad reputation is much slower than the fall into one. The marker doesn’t track the wound. The marker is whatever was visible when the system happened to break symmetry.
I find this more disturbing, not less, than the story I started with. It says scapegoating is structural in a way that doesn’t require anyone to deserve it. It says the same machinery that singles out one group could just as easily have singled out another, and the difference is path dependence. It says “this group did something to deserve it” is exactly the wrong question, because the system would have produced the same behavior toward whatever group ended up in the slot.
This is also not a defense of tribalism, and the original worry can rest. The markers aren’t doing useful work in the simulation. They’re providing the substrate for an asymmetric learning rule to break symmetry on. If you take the markers away the system has nothing to lock onto and the asymmetry just makes everyone slightly more pessimistic about everyone. The pathology is in the update rule, not the categorization. The categorization is just where the pathology gets to land.
Other negative results, briefly
I also ran:
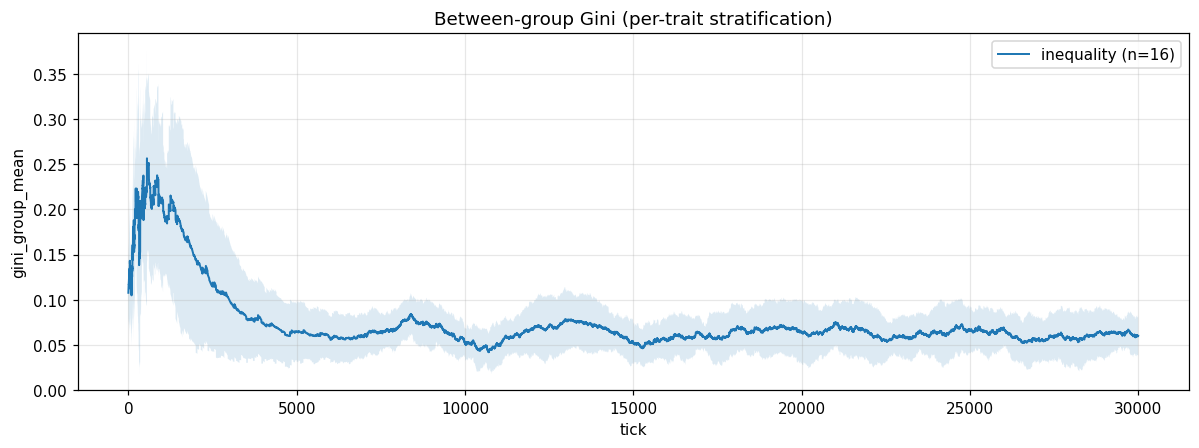
A bimodal-wealth scenario where 30% of agents spawn rich and 70% spawn poor, and rich agents can afford to evaluate more partners before committing. The overall wealth Gini climbed to 0.36 and parked there. The between-group Gini, which is the thing I’d actually want to see if wealth were locking onto traits, stayed near zero the whole run. Wealth stratifies. It doesn’t stratify along trait lines without something extra forcing it to.
A high-turnover scenario with fast spawning and moderate generalization. Newcomers don’t accumulate inherited reputation either, in this setup.
Both of these felt like they should produce stigma and didn’t. The only ingredient I’ve found so far that does produce it is asymmetric updating.
The thing I didn’t expect
While I was characterizing the parameter envelope I noticed something else.
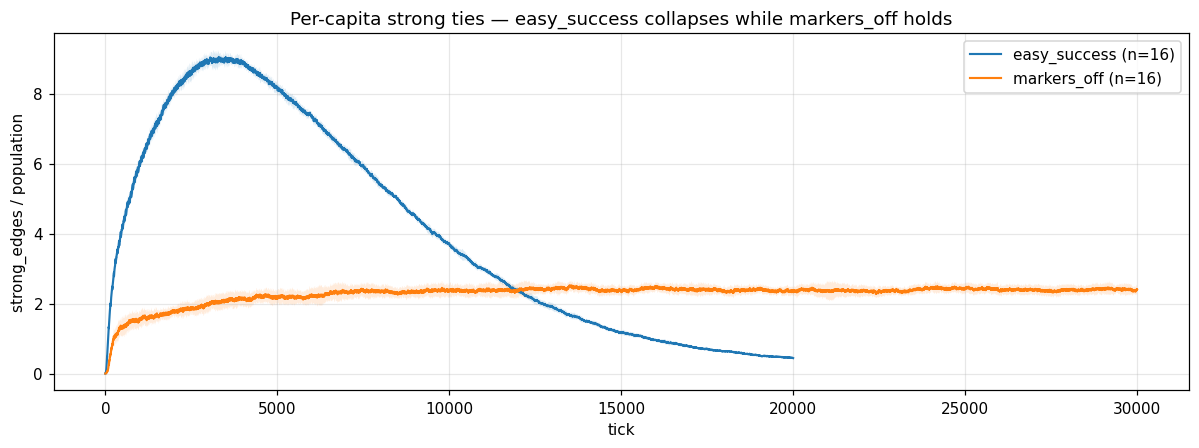
In one regime, easier ventures, more resources, populations that grow into the hundreds, the network of strong relationships does something I haven’t seen flagged in the literature I’ve read so far. Strong-tie count climbs to a peak around tick 6000, then falls back down even as the population keeps growing. By the end of the run the per-capita number of strong ties has dropped about twenty times from peak. Meanwhile the total number of relationships is still climbing, what’s collapsing is strength, not count.
It looks like the system has a maintenance ceiling on strong ties that I didn’t code in. Each agent only generates so many venture outcomes per tick. As the population grows, the share of any given relationship’s attention goes down. Old strong ties starve while new weak ones keep forming. There seems to be an emergent budget for how many strong ties an agent can maintain, and once you push the population past that budget the strong-tie fabric thins out.
It’s a Dunbar number like dynamic falling out of nothing more than the bookkeeping. I find this surprising and I’m going to chase it.
I don’t yet know whether the per-capita strong-tie count stabilizes at some floor, which would be a real emergent capacity law, or keeps collapsing toward zero, which would mean it’s a numerical artifact. I need to run that scenario several times longer than I have to find out.
What I’m doing next
Disentangle loss-aversion’s stigma effect from the fact that loss-averse runs also have smaller populations. Some of the |gap| signal could be small-sample noise. I think I can do this with the data I already have, by plotting the per-seed gap magnitude against the per-seed final population within the loss-averse condition, but a clean control run would be better.
Try a scenario where one group is genuinely a few percent worse at ventures than the other. With symmetric updating, the priors should track the real difference. With loss-averse updating, my prediction is that the priors will overshoot, distrust the worse group more than its actual shortfall warrants. That’d be a sharper claim than what I have now.
Run the easy-success scenario much longer to find the per-capita strong-tie asymptote.
Try recovery: take a seed that’s locked into “distrust group A,” intervene at some tick, bump exploration, dampen the asymmetry, give group A agents a temporary boost, and see whether the lock-in releases or persists. If the lock-in is genuinely path-dependent and not just a slow process, this should be able to tell them apart.
Where I am
Two weeks ago I thought I was looking at a simulation that mildly endorsed tribalism. I wasn’t. I was looking at one that needed a missing ingredient to produce the dynamics I was after, and once I added the ingredient, an ingredient that we already know exists in real human cognition and it produced something more honest than what I was originally looking for.
The simulation isn’t telling me marginalization is bad, or good, or defensible, or arbitrary. It’s telling me that under specific learning rules that match how real people seem to update, some group is going to end up holding the bag, and which group is going to be a matter of history. I have no idea what to make of that. Is that right? I don’t fucking know. Wheeee!
What I do know is that what I’m going to attempt to learn about next is endogenous networks and their capacity for the compounding effects. This is the next article I’m going to sit with, for anyone that had the misfortune of reading this long.
Code is on the github repo. Plots are below. Email’s in the contacts. Critique gratefully received.
Much love, take care of each other.